Blog posts are written by project team members. Topics range from conferences we attend, musings on current affairs of relevance, internal project findings and news and more succinct content which can be found in our Digital Humanities Case studies or project related publications. Blog posts will mainly be posted in English but will from time to time feature in the language of the project team member’s preference, since we are a multilingual bunch! Happy reading!
On Multilingual Dynamic Topic Modeling
In this blog post, Elaine Zosa who works on Dynamic Text Analysis within NewsEye explains a research technique for newspaper research which is of interest to the NewsEye project. Her work, and that of her team members, aims to create dynamic text analysis tools for document collections. Below she describes topic modelling, its various types and how it is relevant to the project.
What is topic modelling and what is it for?
Topic modelling is an unsupervised machine learning method that groups documents according to themes or topics without any prior knowledge of what each document contains. It is useful for automatically classifying document collections, labelling new documents according to its contents and finding documents that discuss similar topics. One advantage of topic modelling over other document classification methods (e.g. Naive Bayes or clustering methods such as K-means clustering) is that it is a mixed-membership model. This means that a document can be classified under several topics in different proportions. For instance, given an article that discusses how concerns about climate change impact elections, this article might be classified as belonging to the politics topic by 20%, science topic by 50% and economics by 30%. Since all of these proportions add up to 100%, this makes the results of topic modelling interpretable to users. The interpretability and unsupervised nature of topic modelling is particularly useful for exploring large document collections such as what we have in NewsEye because it requires few assumptions from the user about the data.
Different kinds of topic models
LDA (Latent Dirichlet Allocation)
There are many different variations of topic modelling depending on what kind of dataset it can process, how it models topics, what other variables it models, and others. LDA (Latent Dirichlet Allocation) is one of the most popular topic modelling methods widely used today. Indeed, many types of topic modelling methods are based on LDA or extensions of it. One of the things that these methods have in common is that the number of topics to be extracted is a hyperparameter, a value that is set by the user and not learned by the method. The `ideal' number of topics depends on many factors such as the use case, the size of the dataset, the limitations of the model, and any prior knowledge the user might have about the collection. To give an idea about what topics can be extracted from newspaper data, we ran LDA on news articles published between 1910 and 1920 in L'Ouevre, a French newspaper from the Gallica collection of the Bibliotheque nationale de France (BnF), our partners within NewsEye.
Figures 1, 2 and 3 are word cloud representations of three topics from this dataset. As we can see, a 'topic' is not a clearly defined subject like a Wikipedia page for example. Instead, a topic is a distribution over the words in the vocabulary and a word cloud is agraphical representation of this distribution. (Side note: methods to represent and visualised topics is a research question that we will also address in NewsEye).

Figure 1: Word cloud of a topic learned by LDA from the L'Ouevre dataset. This topic seems to be about maritime travel.

Figure 2: This topic talks about public transportation.
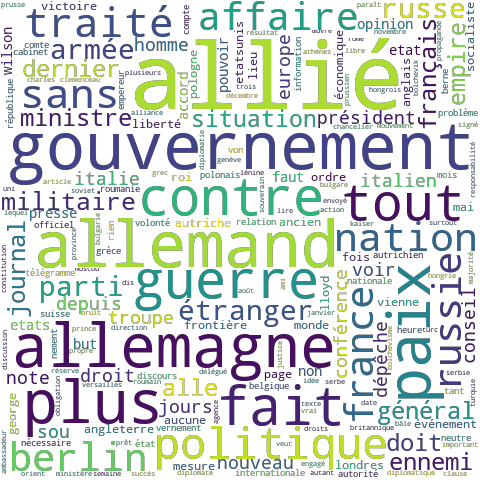
Figure 3: This topic talks about war and politics, possibly during World War I.
Dynamic Topic Model
Another topic modelling method that is particularly useful for newspaper collections is dynamic topic modelling (DTM). DTM is suitable for datasets that cover a span of time or have a temporal aspect (e.g. news articles). Instead of extracting static topics (topics that don't evolve) as in LDA, DTM extracts dynamic topics where each topic evolves over time. Aside from the number of topics, DTM also has the time slicing as a hyperparameter. This means the user has to specify how the method should discretize time (by months, years, decades or other kinds of discretization). With these hyperparameters, DTM learns topics and how they change from one time slice to the next. As with the number of topics in LDA, the question of the ideal granularity of the time slices in DTM depends on several factors, the foremost being the data and user needs.
There are dynamic topic modelling methods that don't require discretisation of time slices but they have their own limitations as well.
We ran DTM on the Uusi Suometar dataset, a Finnish newspaper from the digitized collection of the National Library of Finland (another NewsEye partner!), for 10 topics and 20 time slices (1869 to 1888). Figures 4, 5 and 6 show word clouds for a single topic about international news from three different years (1869, 1877, and 1888). Notice that in 1869, France ('Ranska') is very prominent in the topic but by 1877, France has lost prominence and the topic has moved on to Turkey ('Turkki') and Russia ('Venäjä) and then in 1888, the topic is more about Russia ('Venäjä') and Germany ('Saksa'). From these word clouds, it is possible to trace important historical developments using DTM.

Figure 4: International news topic from 1869 learned by DTM from the Uusi Suometar dataset.

Figure 5: International news topic from 1877 learned by DTM from the Uusi Suometar dataset.

Figure 6: International news topic from 1888 learned by DTM from the Uusi Suometar dataset.
Multilingual Topic Model
Another type of topic model that is of interest to us is the multilingual topic model (MLTM). As the name signifies, this topic model is for multilingual datasets where more than one language is represented (this means that one article can be in say German and another article in French but not cases where a single article exhibits more than one language). The topics that one would get from a MLTM is similar to an LDA topic except that each topic has a separate representation in the different languages that are found in the dataset. There are several ways of doing multilingual topic modelling, some are designed specifically for bilingual corpora while others can handle any number of languages but require some preprocessing of the data.
So why we need another kind of topic model for multilingual datasets when we can just apply LDA on documents from each language separately? The main advantage of MLTM over this approach is that MLTM aligns topics across languages while LDA cannot guarantee this. This is important because one of the benefits of MLTM is that it can be used for cross-lingual document retrieval. For instance, a user might find a German news article of interest and wants to find similar articles in French or Finnish. Without any knowledge of these languages we can retrieve such articles quickly using MLTM.
We applied MLTM on a dataset of Finnish and Swedish news articles from YLE, the Finnish national broadcaster. These articles are written separately but covers the same time period (2012 to 2018) (this dataset is not part of the NewsEye collection but we use it here because it is more convenient to preprocess). Figures 7 and 8 show a topic about sports in Finnish and Swedish, respectively. These word clouds are not direct translations of each other but they show that the method learns related words from both languages just from the data without using external lexical resources such as dictionaries (e.g. ‘ottelu’ in Finnish means ‘match’ in Swedish and ‘pelata’ (to play) means ‘spela’ in Swedish)

Figure 7: Finnish representation of the sports topic from learned by PLTM from YLE articles.

Figure 8: Swedish representation of the sports topic from learned by PLTM from YLE articles.
A new kind of topic model
So the question we are trying to answer which is of significant relevance to NewsEye is: it possible to combine dynamic and multilingual topic modelling to learn evolving topics from multilingual corpora? Yes, it is! We have recently published a paper for a multilingual dynamic topic modelling method (ML-DTM) that does exactly this. MLDTM uses techniques from DTM to model topic evolution and MLTM to learn cross-lingual topics. The experiments we conducted show that our method can detect significant events (e.g. elections) related to a topic and quantitatively demonstrate that our topics are aligned in a cross-lingual manner. This gives us a new topic modelling method that we can apply to the NewsEye collection to gain some interesting insights into historical news.
References
1. Blei, David M., Andrew Y. Ng, and Michael I. Jordan. "Latent dirichlet allocation."
Journal of machine Learning research 3.Jan (2003): 993-1022.
2. Blei, David M., and John D. Lafferty. "Dynamic topic models." Proceedings of the
23rd international conference on Machine learning. ACM, 2006.
3. Wang, Chong, David Blei, and David Heckerman. "Continuous time dynamic topic
models." arXiv preprint arXiv:1206.3298 (2012).
4. Wang, Xuerui, and Andrew McCallum. "Topics over time: a non-Markov continuous time
model of topical trends." Proceedings of the 12th ACM SIGKDD international
conference on Knowledge discovery and data mining. ACM, 2006.
5. Mimno, David, et al. "Polylingual topic models." Proceedings of the 2009 Conference
on Empirical Methods in Natural Language Processing: Volume 2-Volume 2. Association
for Computational Linguistics, 2009.
6. Vulic, Ivan, et al. "Probabilistic topic modeling in multilingual settings: An overview of
its methodology and applications." Information Processing Management 51.1 (2015):
111-147.
7. Arthur, David, and Sergei Vassilvitskii. "k-means++: The advantages of careful seeding." Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms. Society for Industrial and Applied Mathematics, 2007.
8. Manning, Christopher, Prabhakar Raghavan, and Hinrich Schütze. "Introduction to information retrieval." Natural Language Engineering 16.1 (2010): 100-103.