Blog posts are written by project team members. Topics range from conferences we attend, musings on current affairs of relevance, internal project findings and news and more succinct content which can be found in our Digital Humanities Case studies or project related publications. Blog posts will mainly be posted in English but will from time to time feature in the language of the project team member’s preference, since we are a multilingual bunch! Happy reading!
A perspective on research on digitised newspapers at DH2019
Mikko Tolonen is head of the Helsinki Computational History Group.
 Ali Zeeshan")
Over the past decade newspapers and different newspaper projects have become a crucial part of the digital humanities. Australia has its Trove; Europeana has been ongoing for more than ten years, Library of Congress and different libraries in the US are working on newspaper projects; and at the same time different individuals and institutions in South America, Asia and Africa are doing their best to preserve our cultural heritage.
Researchers are also finally getting their hands on data and beginning to work together with libraries for new objectives. In short, different digitisation projects are becoming everyone’s business. It is simply not enough to think about newspaper digitisation as a process where printed objects are turned into a PDF format without a possibility to access and modify the data for research purposes. Andrew Prescott expressed this eloquently during the DH2019 conference by stating that with respect to digitised newspaper collections “searchability has often been an afterthought” and not something integrated to the processes from the beginning. Meanwhile, it is good to remember that still only a fraction of newspapers has actually been digitised (and there are thus chances of learning from past mistakes and establish best practices):
Most striking feature of the discussion of newspaper digitisation at #dh2019 so far is the low percentage of newspapers so far digitised - between about 4% and 6.5% various colleagues suggest.
— Andrew Prescott (@Ajprescott) 10. Juli 2019
Below I will discuss some aspects of research on newspapers visible at DH2019 conference in July 2019 and bring impressions from the conference from its twitter feed.
ADHO in Utrecht 2019

ADHO’s DH2019 conference in Utrecht turned out to be the largest global digital humanities conference to date bringing together more than 1000 participants: Newseye was present with different papers on research undertaken in the project and as interlocutors (two long papers at the conference led by Helsinki Computational History Group and one panel on newspaper digitization).
700 reviewers, 3600 reviews, over 900 proposals, 1000+ #DH2019 participants - E. Pierazzo & F. Ciotti showing us some numbers 'behind the scenes' #DigitalHumanitiespic.twitter.com/Jkau8hnpsN
— ACDH (@ACDH_OeAW) 9. Juli 2019
The conference theme was “Complexities” which is of course crucial with respect to newspapers as well and resonating in DH2019 at different levels. Two full panels were devoted to newspapers alone, there were at least three posters on newspapers and close to ten separate presentations on different aspects of newspapers at the conference. Also some scholars working on newspapers, but not present in Utrecht made a conscious effort to contribute:
This week (while not at #DH2019 of #OzHA2019) I updated, created, and fixed a few things...
— Tim Sherratt (@wragge) 13. Juli 2019
Libraries, newspapers and methods – some insights from the conference
 at The Past, Present & Future of Digital Scholarship with Newspaper Collections")
It was delightful that the relevance of libraries for newspaper projects was not forgotten at DH2019. Questions of copyright and bias were examined both in theory and in practice for example at the Digital Scholarship institute’s panel, “The Past, Present & Future of Digital Scholarship with Newspaper Collections” focusing on a new project called Living with Machines at the British Library. NewsEye took part in this panel through a presentation by Jean-Philippe Moreux. With respect to the panel, Melissa Terras noted on twitter that a visible change in DH is that people are now more critical towards questions of bias and data:
One theme I'm seeing at #DH2019 papers = the issue of data bias, & the critical enquiry into what data allows us/ constricts us in doing (rather than in previous years - how to do it, or yay data cool stuff here's my database). This is a good development in DH. I'm here for it.
— melissa terras (@melissaterras) 11. Juli 2019
 during DH2019 (pictured, newseye’s Jani Marjanen who works on changing vocabularies in different language newspapers.)")
The same applies also to material aspects of print products. While text mining remains the main aspect of DH engagement with newspapers, questions of metadata and materiality are also taken seriously in many newspaper projects, including the NewsEye:
#dh2019#newspapers#impresso#newseye Heritage newspapers digitisation starts with ironing. No funding-no ironing... #BnF technical center, Sablé-sur-Sarthe pic.twitter.com/5TOdDDAwyq
— Jean-Philippe Moreux (@jpmoreux) 10. Juli 2019
One of the Helsinki Computational History Group’s papers that links directly to NewsEye aims to take the questions of materiality to a next level devoting all of its time to this aspect when thinking about the evolution of newspapers as material products that become eventually distinct from newsbooks, pamphlets and books:
If you'd have wanted to see my presentation on analysing the material dimensions of newspapers but didn't fit, the presentation is at https://t.co/tJB8b5JFDm. It isn't completely parseable without the talk, but I'm happy to answer questions #DH2019
— Eetu Mäkelä (@jiemakel) 11. Juli 2019
There was also discussion if this kind of take should be integrated in all newspaper projects:
#DH2019 another great paper on newspaper research, this time by Eetu Mäkelä on Charting the Material Development of Newspapers [in Finland], correlating page sizes, information density and advance in printing techniques
— Torsten Roeder (@torstenroeder) 11. Juli 2019
The idea indeed is that this type of research should be done in a manner that is reusable and scalable to different datasets and projects as well. A lesson learned at the Oceanic exchanges project panel related directly to this desire for common methodology that needs to be more than just a wish:
#DH2019@OceanicEx so many people working with digital newspapers here! Most diverse topics and questions, but: surprisingly many challenges in common. It would be great to develop a methodology together to consolidate own research and support future research projects.
— Torsten Roeder (@torstenroeder) 10. Juli 2019
For example, text reuse in newspapers (that is at the core of Oceanic exchanges -project) is something that can be applied across different datasets. This at the same time connects with the crucial question of data quality. Perhaps one of the most interesting recent developments within the NewsEye project is that the Transkribus engine designed for handwritten text recognition is producing wonderful improvements also with respect to printed newspaper material. Thus, checking out a poster about handwritten text recognition is becoming even more interesting for historians studying newspapers:
At #DH2019 and interested in historical writing, Handwritten Text Recognition, deep annotation etc, for many different scripts? Come to Poster 58, talk to us, play with a demo. https://t.co/quo3HUZcbQhttps://t.co/11qS8mikpJ#Scripta#HTR@psl_univ@EPHE_frpic.twitter.com/vzaB12QGoX
— Peter Stokes (@pa_stokes) 10. Juli 2019
One very delightful aspect of digital research on newspapers is that data releases involving researchers are becoming more and more common parts of different projects. At least two newspaper related data releases were announced during the conference. One on ground truth data:
we're happy to make our #groundtruth of the @NZZ black letter period from 1780 to 1946 available for #research on #OCR improvements! vistit https://t.co/aSd1MXRxTX and get crazy with it! #digitalhumanities#newspapers#NLP#NLProc@UZH_en@UZH_Science@cl_uzh@ImpressoProject
— Phillip Ströbel (@CLingophil) 12. Juli 2019
And another one on word embeddings:
All of the code and all of the word embeddings in Finnish, Swedish, English and Dutch(!) newspapers (1750-1950) from the @NewsEyeEU project, studying 'nations'. By @_shengche et al #DH2019https://t.co/fIbTaLj19l
— Steven Claeyssens (@sclaeyssens) 12. Juli 2019
Future prospects
In the future, contex should be taken seriously with respect to digitisation projects. Project planning still needs to improve though according to Andrew Prescott and others:
I’m glad you find my comments helpful. A lot of what I said is documented in more detail in my article ‘Searching for Dr Johnson: the Digitisation of the Birney Newspaper Collection’ which is available on open access here: https://t.co/WjXoR6hfom#dh2019https://t.co/2IVWqrazJN
— Andrew Prescott (@Ajprescott) 10. Juli 2019
Meanwhile, collaboration is another key objective going forward. One of the great moments of the conference was Maud Ehrmann’s (who leads the Impresso newspaper project) comment that for interoperability with respect to newspapers the road to success is the collaboration between Impresso and NewsEye project:
With respect to interoperability @maudehrmann says that collaboration between @ImpressoProject & @NewsEyeEU is a step towards the right direction and it is hard to disagree. #DH2019
— Mikko Tolonen (@mikko_tolonen) 10. Juli 2019
For collaboration between libraries and researchers a new development was also launched and an “Inventory Researchers Wishlist on digitised newspapers” emerged on the last day of DH2019:
Inspired by conversations about digitised newspapers at #DH2019? Think about the points / rants / lessons you’d share in manifestos by/for researchers and GLAMs https://t.co/ecGIvKo6q8 and join the mailing list https://t.co/aLz6QMBzVo to continue the discussion
— Dr Mia Ridge (@mia_out) 12. Juli 2019
Working groups that unite across different countries should be used also for these undertakings. Newspapers don’t necessarily need a new working group in Dariah (although it would make sense at some level), because many related ones already exist. For example, a new bibliographical data group unites interests in research on newspapers: https://dariah-ae-2019.sciencesconf.org/261699/document and should be followed by relevant newspaper projects.
All of this points towards the fact that open science (or cross-project collaboration in general) is not easy and if the ecosystems aren’t built correctly, it can become a nuisance… But open science is the only way for a more effective work on large digitised historical corpora. This development can also be considered natural because work on newspapers combines memory organisations (different national libraries in particular) and researchers through necessity of working together. It is not only the researchers that have realised this but also library communities (in LIBER for example have been active on this front for some time).
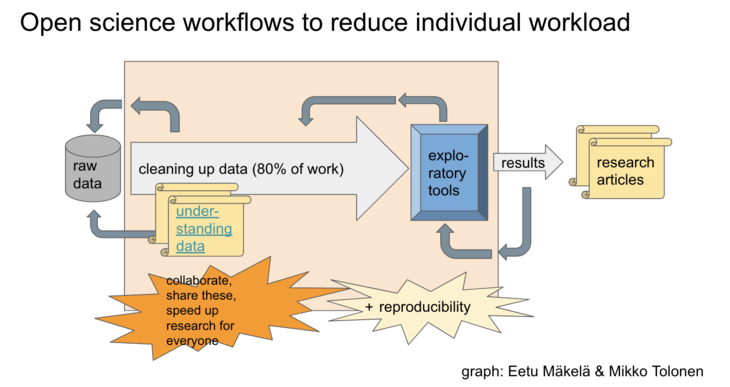
All in all, next time you hear someone complaining about bad OCR in newspapers, think of it as a gateway for realising the inevitable need to think about our work in digital humanities as a mutual process. If the projects remain isolated, we are not going to be able to do DH and impact humanities at large. There should also be incentives from the research funding perspective to encourage this cross-project collaboration to enable sustainability of successfully evolving projects in digital humanities.