Les articles du blog NewsEye sont rédigés par les membres de notre équipe projet. Parmi les thèmes traités figurent les conférences auxquelles nous assistons, des réflexions sur les questions d’actualité pertinentes, des actualités et les avancés de notre projet, ainsi que du contenu plus succinct diffusé dans le cadre de nos études de cas sur les humanités numériques ou de nos publications relatives au projet. Les articles du blog sont publiés principalement en anglais, mais néanmoins proposés de temps à autre dans la langue de prédilection du membre de l’équipe projet concerné, puisque notre petite troupe parle plusieurs langues ! Bonne lecture !
What’s the frequency, Kenneth?
It is common practice in humanities scholarship to trace the first occurrence of a particular keyword. This is sometimes called “the religion of the first occurrence” (James & Steger, 2014). Digitised sources are obviously helpful in identifying new candidates for first uses of particular terms through keyword searches, but more importantly, they make it possible to shift focus from early uses to answering questions of when it became more common in general to use a particular word or when only some people chose to use particular terminology.
Digitised newspapers are a very good data set for diachronic analysis of the frequency of words or other features of language, as they form a comparatively speaking stable corpus that deals with a large selection of topics. It is also relatively easy to select sub corpora based on particular newspapers (perhaps with different political flavour), particular publication places or the publication frequency of newspapers.
Frequencies and historical analysis
For corpus linguistics, the analysis of word frequencies is much about getting at the truth of language use and hence having a balanced corpus is central. It is, however, not an easy task to decide what actually constitutes a balanced corpus as there is not objective measure for how to balance genres or other features in the texts.
For historical purposes, two more levels of uncertainty enter the analysis. First, historians are usually interested in something that goes beyond language use, be it debates, concepts, events or even the limits of what could be said at a given time. This added interpretative layer requires a reflection about what is measured and how that relates to whatever historians are interested in. Second, historical data sets are often more uneven than curated corpora as the materials recorded in a data set have changed themselves over time. For instance, a data set containing hundreds of years of newspapers is a wonderful source to study change in history through language, but any identifiable change is always also about the change in newspapers as a medium, not only the issue a historian is trying to grasp by studying the newspapers. The historians’ interpretation about what changes when changes in word frequencies occur must hence also try to account for changes or bias in data stemming from change in the original series of sources.
Given the popularity of looking at relative frequency as an indicator of changes in history, historical analysis has paid surprisingly little attention to what may cause a peak in relative frequency. In general, changes in word frequencies are about:
- a word becoming topical in a given moment
- a word entering new domains in language
- a word being included in larger linguistic entities such as idioms which might have meaning of their own
- a word is associated with new related meanings (polysemy)
- something data specific that skews frequency
The last case might for instance be about repeated advertisements that include a particular word several times. They are as such surely part of the historical dataset, but would be cleaned out if the data set would be seen as
balanced in a corpus-linguistic sense. Any historical analysis would have to take such cases into account if trying to make claims about historical change.
For now, we also set aside the questions of polysemy and idioms, and focus on the first two cases by looking into the words nationalism and national in Swedish-language newspapers published in Finland between the years 1771 and 1910.
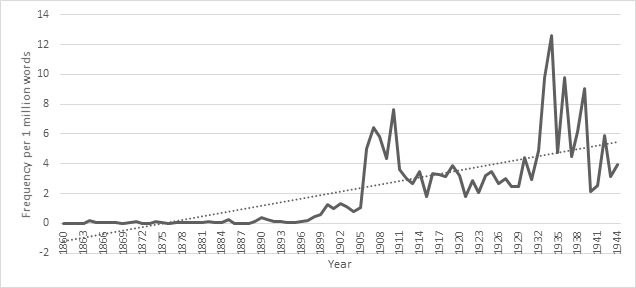
Relative frequency of the lemma nationalism in Swedish-language newspapers and periodicals in Finland. False positives resulting from bad OCR-reading of the word rationalism are omitted.
A reading of some of the uses of nationalism in the late nineteenth century shows that the word was used as a negatively laden way in heated debates about Swedish, Finnish and Russian nationalism in Finland. In fact the most common adjective attributes associated to nationalism are ethnic attributes such as Finnish, Russian and Swedish or negative modifiers like fanatic, narrow-minded, blind or hateful. The rise in frequency of the term nationalism at this time was not only a Finnish phenomenon, but can be seen also in other similar data sets. The growth in frequency for nationalism was clearly about the word becoming topical in certain debates.
In a sense, the use of the word nationalism as a negative label is very similar to the famous passage from Herder, only at the turn of the century 1900, the term also became much more frequent and clearly became a central invective in political debates.
National as an example of a discourse spreading to new contexts
If we turn to the word national, the trend line shows a story of growth in frequency during the nineteenth century, but the change is more gradual and seem to be less connected to particular debates.
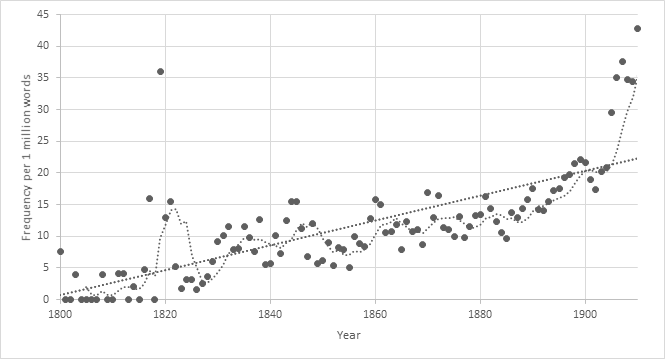
Relative frequency of the lemma nationell in Swedish-language newspapers and periodicals in Finland, 1800–1910.
The fact that the relative frequency of national and nationalism do not quite correspond, suggest that the historical use of them is about slightly different things. Looking at not only the frequency of national, but also looking at the context of the term is in this sense revealing. Since the word national is most often followed by a noun, like in the examples of “national anthem” or “national economy”, we can use the nouns to trace which spectrum of things that could be conceptualized as being national. We can also count how many different nouns co-occur with national each year in the newspaper corpus. This measure looks at the productivity of national, that is, the ability of a word to produce new lexemes. In this case it happens through combining the adjective national with different nouns.
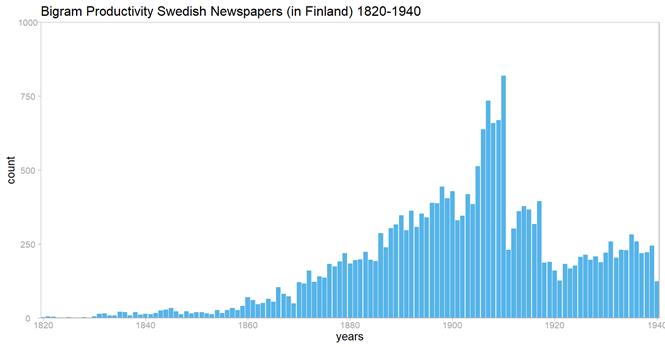
Bigram productivity in Swedish-language newspapers and periodicals in Finland, 1820–1940. The dataset for the period after 1910 is much smaller. Plot created by Ruben Ros.
The increase in productivity indicates that the word national was over the course of the nineteenth century used in more and more domains of language. By the end of the century the nouns co-occurring with national related quite different spheres of life from “national economy” and “national assembly” to things like “national anthem” or “national language”. The increase in productivity for the word national indicates that the growth in frequency is not so much about the term becoming central in debates, but more about the term being used in more and more contexts. Only in the years 1820 and 1821 do we see a clear peak in in relative frequency that can be explained by peaks in political debates. Those years, the papers Mnemosyne and Åbo Underrättelser radicalized the language of national.
The habit of talking about things national in conjunction to nouns also increased over time. In the 30-year period 1800–1829 the corpus includes 119 instances of national. Of these roughly 69 per cent were followed by a noun. In consequent 30-year periods this share grew to roughly 80 percent of 49,246 instances in the period 1890–1919.
Understanding frequency and studying historical processes through language
Frequency analysis for the purpose of historical interpretation still relies on a heavy interpretative component. Historians are often interested in changes in language, but also relating those changes to societal change which always requires a discussion about how changes in language use relate to other changes in society. In the cases of the words national and nationalism, we see that while the words share a root, the concrete uses of the terms differ. This is much due to the rhetorical function that is very often accompanied to the use of different “isms” (Kurunmäki & Marjanen, 2018). Studying the frequency of the word nationalism is thus not a good indicator for studying how people understood the nation or even less how nation building as a process advanced in Finland (or elsewhere), but rather about how debates about nationhood and politics of nationality became heated. Looking at the frequencies of the word national on the other hand does tell as at least something about how the national perspective became dominant. This is also to a certain extent indicative nation building as a process.
After the Google Ngram Viewer was made public several projects used long term changes in relative frequency in word use as indicators for historical change. Many of them prove interesting information for historical research, but some show weaknesses in understanding the nature of the data set and others are naïve regarding the historical interpretations based on word frequencies (Pechenick, Danforth, & Dodds, 2015). For historians to better understand to which extent relative frequency can be used to draw conclusions relating to historical processes, we need to better understand how changes in language use, society and political debates affect the frequency of word use in a given data set.
References
Herder, J. G. von (1774). Auch Eine Philosophie der Geschichte zur Bildung der Menscheit. [Riga].
James, P., & Steger, M. B. (2014). A Genealogy of ‘Globalization’: The Career of a Concept. Globalizations, 11(4), 417–434. doi.org/10.1080/14747731.2014.951186
Kemiläinen, A. (1964). Nationalism; problems concerning the word, the concept, and classification. Jyväskylä: Studia Historica Jyväskyläensia III.
Kurunmäki, J., & Marjanen, J. (2018). A rhetorical view of isms: an introduction. Journal of Political Ideologies, 23(3), 241–255. doi.org/10.1080/13569317.2018.1502939
Pechenick, E. A., Danforth, C. M., & Dodds, P. S. (2015). Characterizing the Google Books Corpus: Strong Limits to Inferences of Socio-Cultural and Linguistic Evolution. PLOS ONE, 10(10), e0137041. doi.org/10.1371/journal.pone.0137041